MemeSonic
How should a meme sound? A meme's punch usually comes from the conflict between its image and its text. We modeled that conflict explicitly, then used it to understand memes and give them a voice.
Conventional multimodal AI assumes image and text reinforce each other. Memes break that assumption on purpose. A smiling dog in a burning room, a shocked face at a totally predictable outcome: the humor, irony, and emotion live in the gap between what you see and what you read. When the two modalities disagree, systems that expect agreement fall apart.
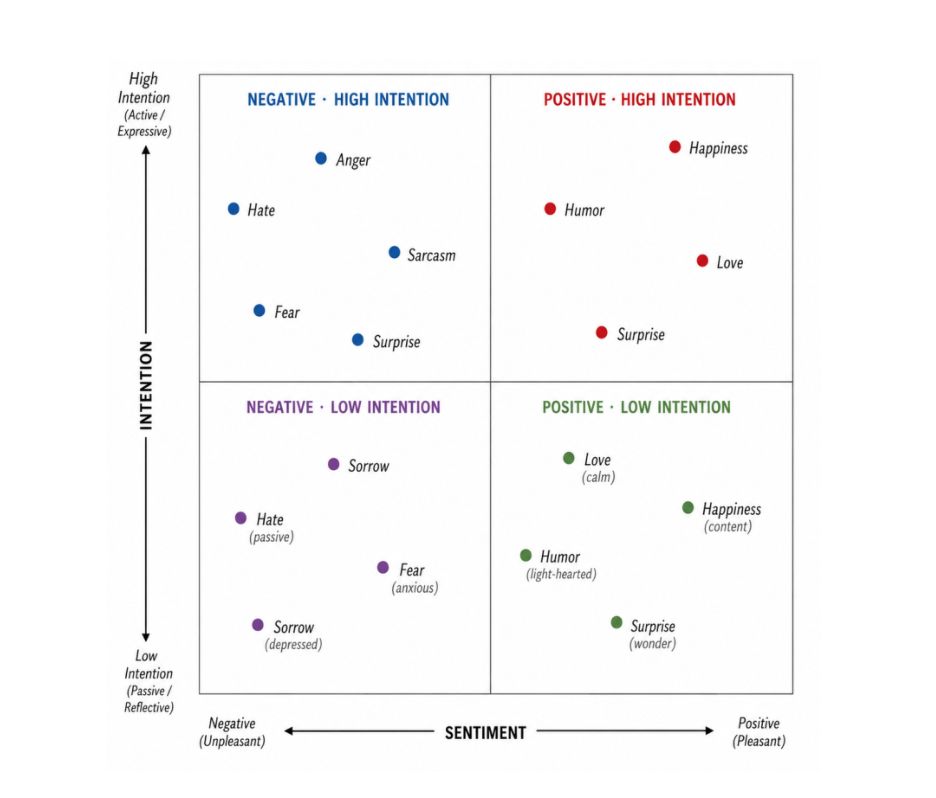
Meme affect is also more structured than a single positive or negative label. It spans both sentiment (pleasant to unpleasant) and intention (active and expressive to passive and reflective), and that is the space any meme affect model has to navigate.
This project changed direction several times before it became MemeSonic.
Starting wide. We began with three candidate directions: decoding meme humor, probing the "language shortcut" in audio-visual models, and a cross-cultural gesture-interpretation benchmark. We downselected to memes as the richest setting for conflict-driven multimodal meaning.
The mid-term version. Our first real design was a bidirectional "meme GIF" product that bridged generation and retrieval. It would read a meme's mood into a human-readable intermediate layer (mood, tone, tags), generate expressive voiceover and synchronized GIFs with persona voice cloning, and let users retrieve memes by vibe. The bet was interpretability and user control.
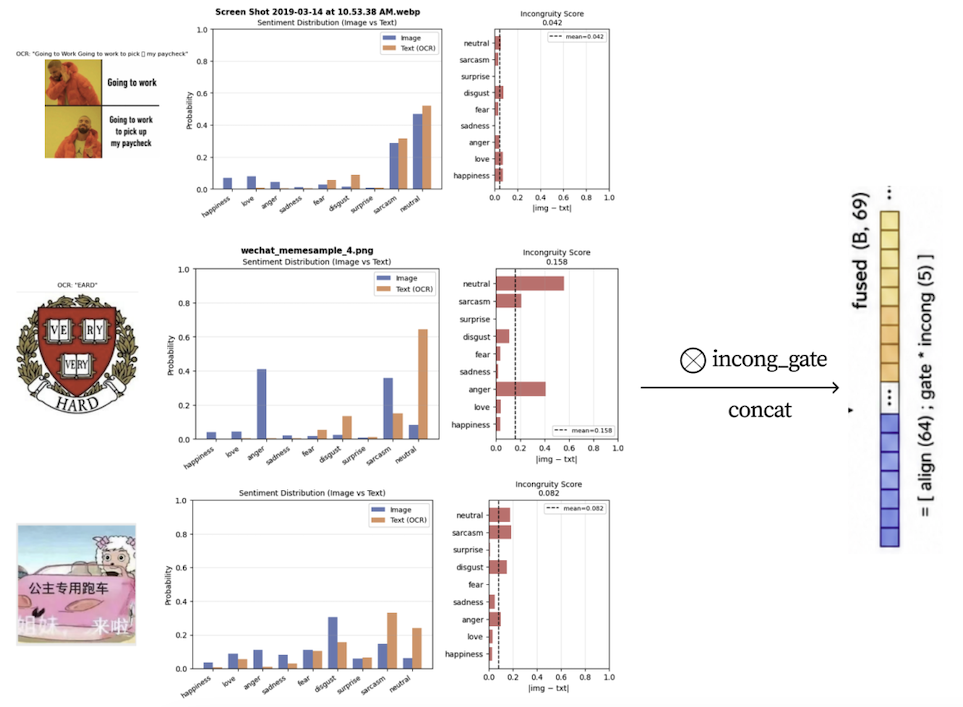
The pivot. That scope was broad and hard to evaluate rigorously. We cut retrieval, GIF output, and voice cloning, and focused on the most fundamental, testable claim underneath all of it: that image-text incongruity is an explicit, usable signal. Everything got reorganized around a single continuous incongruity score.
The impact. Narrowing the scope is what made the work measurable. The sharpened version produced clear wins on sarcasm and metaphor understanding, expressive voiceover that listeners preferred, and a clean diagnostic result on whether speech carries affective signal at all. It also surfaced an honest negative finding: incongruity is not universally helpful, which pointed to a concrete next step.
MemeSonic is built on three ideas:
- Explicit affect decomposition. Read image and text emotions separately, then quantify their disagreement as a continuous incongruity score instead of averaging them into one blurry embedding.
- Incongruity-aware MoE fusion (FusionMoE). Route each meme through fusion experts for redundancy, complementarity, and conflict, with a learned router that picks the right strategy per sample rather than forcing one fusion style on every meme.
- Meme-to-speech pipeline. Translate the meme's affect into prosody and synthesize expressive voiceover, turning implicit pragmatic affect into an audible signal.
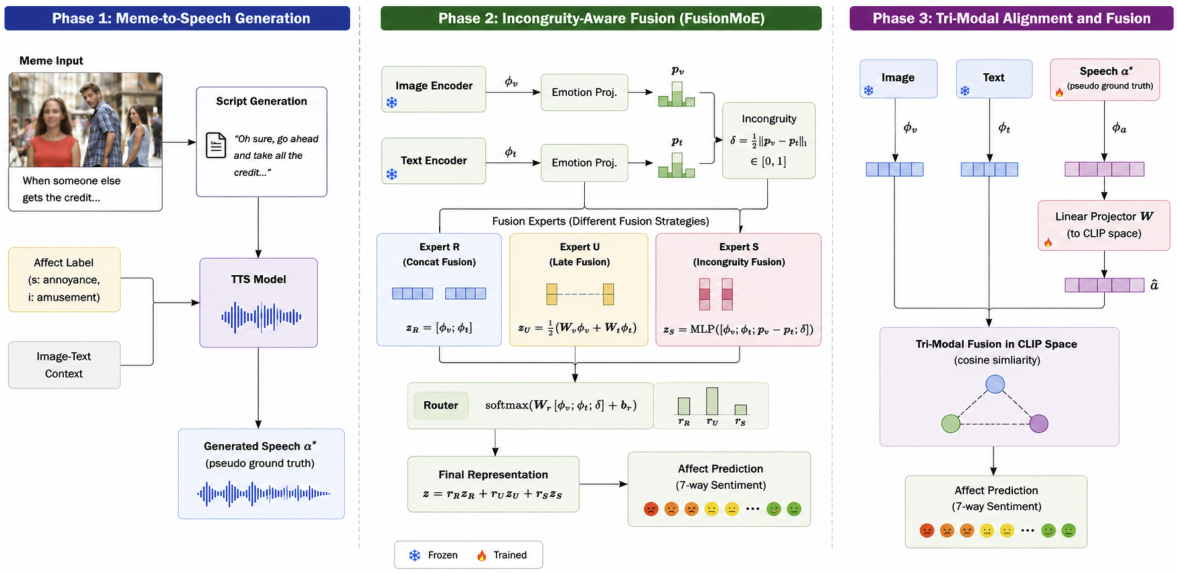
The full system runs in three phases: meme-to-speech generation, incongruity-aware fusion, and a tri-modal stage that tests whether generated speech adds affective signal beyond image and text.
A short walkthrough of the prototype: select a meme, watch the image and text emotions separate, read the incongruity score, apply a mood, and hear the voiceover change. Turn your sound on.
Expressive voiceover. MemeSonic's prosody adapter beat both vanilla and label-only TTS on expressiveness and pragmatic appropriateness while keeping naturalness comparable. Listeners preferred it 84.7% of the time over vanilla TTS.
| Method | NMOS | EMOS | AMOS |
|---|---|---|---|
| Vanilla TTS | 3.92 | 2.35 | 2.42 |
| Label-Guided TTS | 3.85 | 3.12 | 3.05 |
| MemeSonic | 3.88 | 3.86 | 3.95 |
Incongruity-aware understanding. Modeling conflict explicitly helped most where meaning depends on image-text contradiction. FusionMoE beat conventional fusion by up to +14.5% Macro-F1, with the largest gains on metaphor and sarcasm. Reasoning LLMs were strong on commonsense-heavy tasks, but trained models stayed more reliable on structured affect.
| Method | Sentiment | Sarcasm | Metaphor | MMSD |
|---|---|---|---|---|
| Concat Fusion | 31.0 | 30.2 | 82.9 | 82.6 |
| Late Fusion | 27.8 | 32.1 | 81.8 | 82.0 |
| MULT | 24.3 | 28.4 | 84.7 | 83.0 |
| FusionMoE | 26.8 | 25.3 | 87.6 | 84.0 |
Speech as a third modality. Naively adding speech did nothing. After a learned projector aligned speech into the shared space, sentiment accuracy jumped from 0.27 to 0.82. The obstacle was modality mismatch, not a lack of signal in the speech.
| Setting | Accuracy | Macro-F1 |
|---|---|---|
| Image only | 0.15 | 0.38 |
| Image + Text | 0.27 | 0.45 |
| Image + Text + Audio (naive) | 0.27 | 0.45 |
| Image + Text + Audio (aligned) | 0.82 | 0.49 |
We kept an honest negative result too: incongruity is not universally useful. It added noise on tasks driven by holistic semantics rather than conflict, such as intention and humour, which points to task-adaptive gating of the incongruity signal.
MemeSonic was a three-person project (Yiqiao Huang, Hongbee Park, Ruyi Yang) for MIT Media Lab MAS.S60, Spring 2026.
I proposed the core idea, owned the related-work research end to end, and integrated the components each teammate built into the final interactive demo product.
- Build meme-native datasets with aligned image, text, affect, intention, and voiceover annotations
- Joint tri-modal pre-training so image, text, and speech share a space from the start
- Task-adaptive gating so incongruity is used only where conflict actually drives meaning
- Extend incongruity beyond memes to news captions, political cartoons, and short-form video